引言
渗透测试之前要对目标系统作充足的信息收集,信息收集得越全,与目标系统交互得越少,效果也就越好。
分类
-
主动信息收集
直接与目标系统进行交互,攻击者流量经过系统,容易留下痕迹,但是收集到的信息更全
-
被动信息收集
利用网络上的服务,如搜索引擎在线工具等对目标进行查询收集,流量由第三方发送给目标网站,能搜集到一些基本的信息
域名信息收集
概念
-
什么是域名
域名是由一串用点分隔的名字组成的Internet上某一台计算机或计算机组的名称,用于数据传输时对计算机的定位标识,由于IP具有不方便记忆并不能显示地址组织的名称和性质等缺点,人们设计出了域名,并通过网域名称系统(DNS domain name system)来讲IP与域名互相映射,使人们更加方便地访问互联网,而不用去记住能被机器直接读取地IP数字串。
-
分层
顶级域: 包括组织域net、edu、com、gov、org等等 国家地区域cn、uk
二级域名: baidu、taobao…
三级域名: mail、www
域名 团体 gov 政府部门 com 商业部门 edu 教育部门 org 民间团体组织 net 网络服务机构 mil 军事部门 -
DNS查询过程
参见–>Linux中搭建DNS服务器
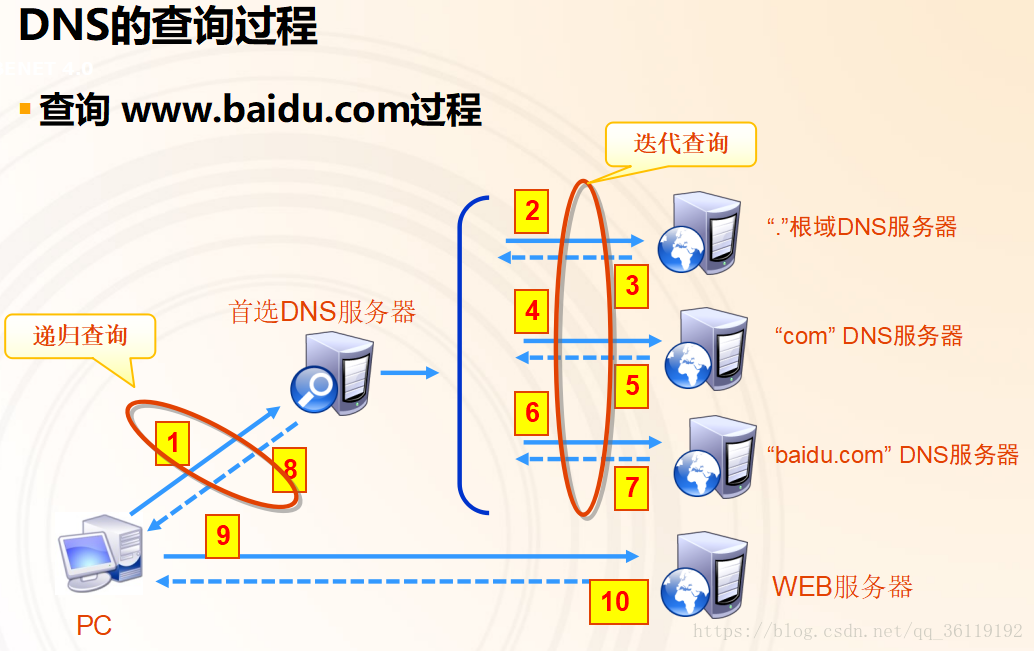
客户机访问域名,先查看自己主机的DNS缓存(有时间限制),如果主机DNS缓存有,则直接访问对应ip。
如果主机DNS缓存没有,则查看本地 hosts文件。
如果 hosts 文件没有,则将该请求发送给主机指定的域名服务器。域名服务器收到请求后,先查询本地的缓存,如果有该纪录项,则域名服务器就直接把查询的结果返回。如果指定的域名服务器的缓存中没有该记录,则进行以下迭代查询。
本地域名服务器向根域名服务器查询,根域名服务器告诉它下一步到哪里去查询,然后它在根据结果逐层向下查询,直到得到最终结果。每次它都是以DNS客户机的身份去各个服务器查询,即迭代查询是本地服务器进行的操作。
-
解析记录
类型 说明 A 主机记录,记录域名对应的IP PTR 反向地址解析记录,记录IP对应的域名 CNAME 别名记录 MX 邮箱交换记录 NS 服务器记录 SOA 权威记录 TXT 为记录说明 SRV 列出正在提供特定服务的服务器 AAAA IPv6地址记录 -
nslookup
nslookup命令是用来诊断DNS基础结构的命令,查询域名信息非常有用的命令,可以指定查询的类型,可以查到DNS记录的生存时间还可以指定使用哪个服务器进行解析。
-
A记录
记录域名对应的IP,通俗来讲A记录就是服务器的IP,通过绑定A记录就是告诉DNS,访问对应域名的时候引导向设置在DNS的A记录对应的服务器。
-
PTR记录
相对于A记录就是把IP地址转化为对应的域名
-
CNAME
别名记录,允许将多个域名映射到同一台电脑上
如果a.baidu.com 是A记录,(a1 a2 a3).baidu.com是CNAME记录的话,如果访问a1.baidu.com,域名解析服务器会返回一个CNAME记录,并且指向a.baidu.com,此时我们的电脑又会发出一个请求解析a.baidu.com,然后域名解析服务器就会返回a.baidu.com的IP地址 如果服务器的IP更换了,那么我们只需要更改A记录对应的IP就可以了。
-
MX记录
MX记录的权重对 mail 服务是很重要的,当发送邮件时,Mail 服务器先对域名进行解析,查找 mx 记录。先找权重数最小的服务器(比如说是 10),如果能连通,那么就将发送过去;如果无法连通 mx 记录为 10 的服务器,那么才将邮件发送到权重为 20 的 mail 服务器上。
这里有一个重要的概念,权重 20 的服务器在配置上只是暂时缓存 mail ,当权重 20 的服务器能连通权重为 10 的服务器时,仍会将邮件发送的权重为 10 的 Mail 服务器上。当然,这个机制需要在 Mail 服务器上配置。
-
TXT记录
TXT记录一般是为某条记录设置说明,比如你新建了一条 a.ezloo.com 的TXT记录,TXT记录内容”this is a test TXT record.”,然后你用 nslookup set type=txt a.ezloo.com ,你就能看到”this is a test TXT record”的字样。
除外,TXT还可以用来验证域名的所有,比如你的域名使用了Google的某项服务,Google会要求你建一个TXT记录,然后Google验证你对此域名是否具备管理权限。
-
AAAA记录
AAAA记录是一个指向IPv6地址的记录。
-
NS记录
域名服务器记录,用来指定域名由哪台服务器进行解析
-
TTL值
TTL=time to live,表示解析记录在DNS服务器中的缓存时间。比如当我们请求解析www.ezloo.com的时候,DNS服务器发现没有该记录,就会向下个NS服务器发出请求
获得记录之后,该记录在DNS服务器上保存TTL的时间长度。
当我们再次发出请求解析www.ezloo.com 的时候,DNS服务器直接返回刚才的记录,不去请求NS服务器。
TTL的时间长度单位是秒,一般为3600秒
-
SOA记录
定义了该域中的权威名称服务器
-
SRV
列出正在提供特定服务的服务器
-
方式
-
whois查询
whois 是用来查询域名的IP以及所有者等信息的传输协议。
简单说,whois就是一个用来查询域名是否已经被注册,以及注册域名的详细信息的数据库(如域名所有人、域名注册商),不同域名后缀的Whois信息需要到不同的Whois数据库查询。
通过whois来实现对域名信息的查询,可以得到注册人的姓名和邮箱信息通常对测试个人站点非常有用,因为我们可以通过搜索引擎和社交网络挖掘出域名所有人的很多信息。
-
站长工具
http://whois.chinaz.com/
-
阿里云中国万网查询
https://whois.aliyun.com/
-
Robtex DNS
查询显示关于目标网站的全面的DNS信息:https://www.robtex.com/
-
站长工具爱站查询
https://whois.aizhan.com/
-
全球Whois查询
https://www.whois365.com/cn/
-
-
备案信息查询
网站备案信息是根据国家法律法规规定,由网站所有者向国家有关部门申请的备案,是国家信息产业部对网站的一种管理途径,是为了防止在网上从事非法网站经营活动,当然主要是针对国内网站。
在备案查询中我们主要关注的是:单位信息例如名称、备案编号、网站负责人、法人、电子邮箱、联系电话等。
-
ICP/IP地址/域名信息备案管理系统
http://beian.miit.gov.cn/publish/query/indexFirst.action
-
ICP备案查询网
http://www.beianbeian.com/
-
备案吧吧
https://www.beian88.com/
-
天眼查
-
-
kali工具
-
Dnsenum
dnsenum的目的是尽可能收集一个域的信息,它能够通过谷歌或者字典文件猜测可能存在的域名,以及对一个网段进行反向查询。
它可以查询网站的主机地址信息、域名服务器、mx record(函件交换记录),在域名服务器上执行axfr请求,通过谷歌脚本得到扩展域名信息(google hacking),提取自域名并查询,计算C类地址并执行whois查询,执行反向查询,把地址段写入文件
用法:dnsenum [选项] <域名>
-
子域名信息收集
-
为什么收集子域名
子域名枚举可以在测试范围内发现更多的域或子域,这将增大漏洞发现的几率,有些隐藏的、被忽略的子域上运行的应用程序可能帮助我们发现先重大的漏洞。
在同一组织中的不同于或应用程序中往往存在相同的漏洞
或者说,假设我们目标网络规模比较大,直接从主域入手显然是很不理智的,因为对主域都是重点防护区域,所以不如先进入目标的某个子域,然后再想办法迂回接近真正的目标。
某些域名站点可能是当时测试创建的,但是没有及时关闭,也可以从该点进入。
方法
利用搜索引擎
- google:
参见–>google黑语法
名称 作用 site 域名 inurl 用于搜索网页上包含的URL,这个语法对寻找网页上的搜索,帮助之类的很有用. intext 只搜索网页<body>部分中包含的文字(也就是忽略了标题、URL等的文字) filetype 搜索文件的后缀或者扩展名 intitle 限制你搜索的网页标题. link 可以得到一个所有包含了某个指定URL的页面列表. 作用 使用 查找后台地址 site:域名 inurl:login\admin\manage\member\admin_login\login_admin\system\login\user\main\cms 查找文本内容 site:域名 intext:管理\后台\登陆\用户名\密码\验证码\系统\帐号\admin\login\sys\managetem\password\username 查找可注入点 site:域名 inurl:aspx\jsp\php\asp 查找上传漏洞 site:域名 inurl:file\load\editor\Files 找eweb编辑器 site:域名 inurl:ewebeditor\editor\uploadfile\eweb\edit 存在的数据库 site:域名 filetype:mdb\asp# 查看脚本类型 site:域名 filetype:asp/aspx/php/jsp 迂回策略入侵 inurl:cms/data/templates/images/index/ 利用谷歌黑客快速找到自己想要的资料:site:qiannao.com 提权视频
-
shodan
要搜索需要先注册 |语法|意义| |:-:|:-:| port|开放端口 country:”“|国家 product:”“|服务器 os:”“|操作系统 city:”“|城市 version:”“|版本 org:”“|组织 http.title:”“|筛选标题中含有关键字的结果 http.status|http请求返回响应码的状态 http.server|http请求返回中server的类型
-
使用图标哈希值搜索favicon.ico
网页的图标文件web icon、page icon
如上图,这个就是百度的Favicon.ico
使用shodan或者firefox的shodan插件

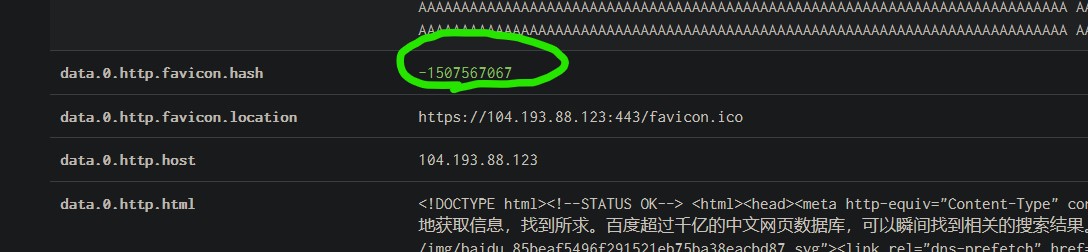
然后搜索框搜索哈希值相关

就可以搜索到含有该图标的结果
或者在shodan中直接点击相应的icon也可以直接查询
-
-
fofa
https://fofa.so/
详细用法见fofa网站
-
zoomeye
- 地理位置
语法 作用 注 country:”” 搜索对应国家资产 可以用英文缩写,也可以使用中/英文全称 subdivisions:”” 搜索相关指定行政区对应资产 中国省会支持拼音及汉字书写如subdivisions:”北京”subdivisions:”beijing” city:”” 搜索城市相关资产 中国城市支持拼音及汉字书写如city:”changsha”city:”长沙” - 证书搜索
语法 作用 注 ssl:”” 搜索ssl证书存在某字符串的资产 常常用来提过产品名及公司名搜索对应目标 - IP及域名信息相关搜索
语法 作用 注 ip:”” 搜索指定ipv4或者ipv6地址相关资产 cdir:52.2.254.36/8 搜索该IP地址A段资产 cidr:52.2.254.36/16 为IP的B段资产 cidr:52.2.254.36/24 为IP的C段资C产,如 org:”北京大学” 或者organization:”北京大学” 搜索相关组织(Organization)的资产 常常用来定位大学、结构、大型互联网公司对应IP资产 isp:”” 搜索相关网络服务提供商的资产 asn:42893 搜索对应ASN(Autonomous system number)自治系统编号相关IP资产 port:80 搜索相关端口资产 目前不支持同时开放多端口目标搜索 hostname:google.com 搜索相关IP”主机名”的资产 site:baidu.com 搜索域名相关的资产 常常使用来搜索子域名匹配 - 指纹搜索
语法 作用 注 app:”Cisco ASA SSL VPN” 搜索思科ASA-SSL-VPN的设备 更多的app规则请参考”导航”,在搜索框输入"思科"等关键词会有相关app提示 service:”ssh” 搜索对应服务协议的资产 常见服务协议包括:http、ftp、ssh、telnet等等(其他服务可参考搜索结果域名侧栏聚合展示) device:”router” 搜索路由器相关的设备类型 常见类型包括router(路由器)、switch(交换机)、storage-misc(存储设备)等等(其他类型可参考搜索结果域名侧栏聚合展示) os:”RouterOS” 搜索相关操作系统 常见系统包括Linux、Windows、RouterOS、IOS、JUNOS等等(其他系统可参考搜索结果域名侧栏聚合展示) title:”Cisco” 搜索html内容里标题中存在”Cisco”的数据 - 时间节点
语法 作用 注 after:”2020-01-01” 搜索更新时间为”2020-01-01”以后的资产 after与before常常配合使用 before:”2020-01-01” 搜索更新时间在”2020-01-01”以前的资产 after与before常常配合使用
利用在线工具
-
DNSdumpster
https://dnsdumpster.com/
-
whois反查
-
virustotal
www.virustotal.com
-
在线子域名爆破
https://phpinfo.me/domain/
-
IP反查绑定域名
http://dns.aizhan.com/
-
https://hackertarget.com/find-dns-host-records/
-
https://site.ip138.com
-
证书查询
crt.sh:https://crt.sh censys:https://censys.io
手动工具枚举
-
layer子域名挖掘机
-
kali工具
-
dnsrecon
简介:dnsrecon是一款多线程、支持爆破、支持多种DNS记录查询、域传送漏洞检测、对IP范围查询、检测NS服务器缓存、结果可保存为多种格式的工具。
用法: -h, –help 打印帮助信息并退出
-d, –domain
目标域名 -r, –range
对给定格式的IP范围进行爆破,格式为(开始IP-结束IP)或(范围/掩码). -n, –name_server
指定一个域名服务器 -D, –dictionary
用来爆破的子域名与主机名字典文件 -f 在保存结果时忽略枚举域查找结果
-t, –type
指定枚举类型:
std 如果NS服务器的域传送失败,进行SOA、NS、A、AAAA、MX 和 SRV的枚举(必须使用-d参数指定域名才可使用此参数) rvl 对给定的IP范围或CIDR进行反向查找(必须使用-r指定IP范围) brt 使用指定的字典爆破域名与主机名 srv 枚举SRV记录 axfr 对所有的NS服务器进行域传送测试 goo 对子域名和host进行Google搜索 snoop 对-D选项给出的文件进行DNS服务器缓存侦测 tld 删除给定域的TLD并测试在IANA中注册的所有的TLD zonewalk 使用NSEC记录进行DNSSEC域漫游-a 在标准枚举过程中进行空间域传送测试
-s 在标准枚举过程中进行IP地址范围的反向查找
-g 在标准枚举的过程中进行Google枚举
-w 在标准枚举的过程中进行深度whois查询和IP反查
-z 在标准枚举的过程中进行DNSSEC域漫游
–threads <number> 指定线程数
–lifetime <number> 指定查询等待的时间
–db <file> 将结果存储为sqlite3数据库的文件
–xml <file> 将结果存储为XML格式的文件
–iw 即使发现了通配符也依然爆破
-c, –csv <file> CSV格式的文件
-j, –json <file> json文件
-v 显示爆破的过程
-
fierce
简介:fierce可以查询域名下的DNS,以及子域名和IP地址信息
用法:fierce <-dns example.com> [options]
该工具首先测试是否有域传送漏洞,若存在则应该直接通过域传送搜集子域信息,没有域传送漏洞则采用爆破的方式。
fierce -dns <域名>
fierce -dns <域名> -threads 100 // threads 是线程数,可以自己指定
-
站点信息收集
CMS指纹识别
什么是指纹?
网站指纹是 Web 服务组件在开发时留下的类型、版本等标记信息,包括 Web 服务器指纹、Web 运用指纹及前端框架指纹等。
CMS(内容管理系统)又称为整站系统或文章系统,用于网站内容管理。用户只需要下载对应的CMS软件包,就能部署搭建,并直接利用CMS。但是各种CMS都具有其独特的结构命名规则和特定的文件内容,因此可以利用这些内容来获取CMS站点的具体软件CMS与版本。
在渗透测试中,对进行指纹识别是相当有必要的,识别出相应的CMS,才能查找与其相关的漏洞,然后才能进行相应的渗透操作。
工具
-
在线识别
BugScaner: http://whatweb.bugscaner.com/look/
潮汐指纹:http://finger.tidesec.net/
能判断是否使用了CDN云悉:http://www.yunsee.cn/info.html
WhatWeb: https://whatweb.net/
云悉指纹: http://www.yunsee.cn/finger.html
-
工具
-
whatweb
-
webrobot
-
椰树
-
-
手工识别
-
根据HTTP响应头判断,重点关注X-Powered-By、cookie等字段
-
根据HTML 特征,重点关注 body、title、meta等标签的内容和属性。
-
根据特殊的class判断。HTML 中存在特定 class 属性的某些 div 标签,如<body class=”ke-content”>
-
敏感目录/文件收集
对网站进行目录扫描,探测web目录结构和隐藏文件是个非常重要的环节,从中可以获取网站的后台管理页面、文件上传界面、robots.txt,甚至可能扫描出备份文件从而得到网站的源代码。
工具
-
御剑目录扫描
-
dirbuster目录扫描
在URL to fuzz里输入“/{dir}”。这里的{dir}是一个变量,用来代表字典中的每一行,运行时{dir}会被字典中的目录替换掉。
-
dirsearch
使用方法
python dirsearch.py -u <网址> -e [extensions]
-e *代表所有
扫描完毕后会在目录下生成txt纯文本格式文件
WAF识别
- 概念
参见–>WAF的工作原理和绕过浅析
Web应用防护系统(也称为:网站应用级入侵防御系统。英文:Web Application Firewall,简称: WAF)。
利用国际上公认的一种说法:Web应用防火墙是通过执行一系列针对HTTP/HTTPS的安全策略来专门为Web应用提供保护的一款产品。
在实际的渗透测试过程中,经常会碰到网站存在WAF的情况。
网站存在WAF,意味着我们不能使用安全工具对网站进行测试,因为一旦触碰了WAF的规则,轻则丢弃报文,重则拉黑IP。
所以,我们需要手动进行WAF的绕过,而绕过WAF前肯定需要对WAF 的工作原理有一定的理解。
-
wafw00f
-
发送正常的HTTP请求,然后分析响应,这可以识别出很多WAF。
-
如果不成功,它会发送一些(可能是恶意的)HTTP请求,使用简单的逻辑推断是哪一个WAF。
-
如果这也不成功,它会分析之前返回的响应,使用其它简单的算法猜测是否有某个WAF或者安全解决方案响应了我们的攻击。
-
敏感信息泄露
有时候,针对某些安全做得很好的目标,直接通过技术层面是无法完成渗透测试的。
此时,便可以利用搜索引擎搜索目标暴露在互联网上的关联信息。
例如:数据库文件、SQL注入、服务配置信息,甚至是通过Git找到站点泄露源代码,以及Redis等未授权访问、Robots.txt等敏感信息,从而达到渗透目的。
google hacking
-
语法
intext:寻找正文中含有关键字的网页
intitle:寻找标题中含有关键字的网页
allintitle:用法和intitle类似,只不过可以指定多个词
inurl:搜索url中含有关键词的网页
allinurl:用法和inurl类似,只不过可以指定多个词
site:指定访问的站点
filetype:指定访问的文件类型
link:指定链接的网页
related:搜索相似类型的网页
info:返回站点的指定信息,例如:info:www.baidu.com 将返回百度的一些信息
phonebook:电话簿查询美国街道地址和电话号码信息
Index of:利用 Index of 语法可以发现允许目录浏览的web网站,就像在本地的普通目录一样
-
查找指定网站后台
site:xx.com intext:管理
site:xx.com inurl:login
site:xx.com intitle:后台
-
查看指定网站的文件上传漏洞
site:xx.com inurl:file
site:xx.com inurl:load
-
利用Index of可以发现允许目录浏览的web网站,就像在本地的普通目录一样
index of /admin
index of /passwd
index of /password
index of /mail
“index of /” +passwd
“index of /” +password.txt
“index of /config”
用index of目录列表列出存在于一个web服务器上的文件和目录。
intitle:index.of 这里的休止符代表的是单个字母的通配符
-
备份文件泄露
intitle:index.of index.php.bak
inurl:index.php.bak
intitle:index.of www.zip
-
查找sql注入
inurl:?id=1
inurl: php?id=
-
-
GHDB 谷歌黑客数据库
链接:https://www.exploit-db.com/google-hacking-database/
黑客们能通过简单的搜索框在网络中出入于无形,在这背后还有一个强大的后盾,那就是Google Hacking Database(GHDB)
这是全世界的黑客朋友们自发维护的一个汇集着各种已经被优化的查询语句的数据库,每天都在不断地更新各种好用有效的Google查询语句。
github信息泄露
-
概念
GitHub作为开源代码平台,给程序员提供了很多便利,但如果使用不当,比如将包含了账号密码、密钥等配置文件的代码上传了,导致攻击者能发现并进一步利用这些泄露的信息,就是一个典型的GitHub敏感信息泄露漏洞。
再如开发人员在开发时,常常会先把源码提交到github,最后再从远程托管网站把源码pull到服务器的web目录下,如果忘记把.git文件删除,就造成此漏洞。
利用.git文件恢复网站的源码,而源码里可能会有数据库的信息
参见–>Git与Git文件导致源码泄露
-
git
在一个目录中初始化一个仓库以后 , 会在这个目录下产生一个名叫 .git 的隐藏文件夹(版本库)这个文件夹里面保存了这个仓库的所有版本等一系列信息
-
-
githack
可以根据.git文件对网站源码进行下载恢复。
服务器信息收集
web服务器指纹识别
-
概念
Web服务器指纹识别是了解正在运行的web服务器类型和版本,目前市场上存在几种不同的web服务器提供商和软件版本,了解被测试的web服务器的类型,能让测试者更好去测试已知漏洞和大概的利用方法
-
主要了解信息
1、Web服务器名称,版本
2、Web服务器后端是否有应用服务器
3、数据库(DBMS)是否部署在同一主机(host),数据库类型
4、Web应用使用的编程语言
5、Web应用框架
-
方法
-
手工检测
1.查看http头信息
2.协议行为:
即从HTTP头字段顺序分析,观察HTTP响应头的组织顺序,因为每个服务器都有一个内部的HTTP头排序方式3.浏览并观察网站
我们可以观察网站某些位置的HTML源码(特殊的class名称)及其注释(comment)部分,可能暴露有价值信息。观察网站页面后缀可以判断Web应用使用的编程语言和框架。4.刻意构造错误
错误页面可以给你提供关于服务器的大量信息。可以通过构造含有随机字符串的URL,并访问它来尝试得到404页面。 -
工具检测
whatweb
whatweb能够识别各种关于网站的详细信息包括:CMS类型、博客平台、中间件、web框架模块、网站服务器、脚本类型、JavaScript库、IP、cookie等等
批量扫描:
使用whatweb -i 含有需要扫描的域名的文件的路径详细回显扫描:
whatweb -v 域名
-
真实IP地址识别
概念
在渗透测试中,一般只会给你一个域名,那么我们就要根据这个域名来确定目标服务器的真实IP,我们可以通过像www.ip138.com这样的IP查询网直接获取目标的一些IP及域名信息,但这里的前提是目标服务器没有使用CDN。
-
什么是边缘服务器?
参见–>什么是边缘服务器?
随着互联网的发展,用户对网站的响应速度,网站内容的可靠性还有即时性要求也越来越高,这使得单台服务器来支撑整个网站的系统已经无法满足客户的需求。
所以取而代之的是两到三层架构的一组服务器,其中第一层直接与客户发生联系的就是边缘服务器。
-
边缘服务器提供一个进入网络的通道和与其他设备服务器进行通讯的功能,通常边缘服务器是一组完成单一功能的服务器,比如防火墙服务器,高速缓存服务器,负载均衡服务器,DNS服务器等。
-
第二层是中间层,也称为应用服务器,包括web表现服务器,web应用服务器等
-
第三层是后端数据库服务器。
防火墙服务器:比如说防火墙,在网站访问数量不高时防火墙功能可以和web服务共同处在同一服务器上,但是当访问网站的客户数量变大时必将增大服务器的负载,防火墙的运行必将影响访问速度,因此为了不降低访问速度甚至是提高访问问速度并且同时保证网站的安全性,就有必要采用专门的防火墙服务器。
高速缓存服务器:用户的等待时间将会导致收入的损失,很多用户在访问网站慢的情况下就会直接转向其他网站,为了提高网站的访问速度和效率,在web服务器之前增加高速缓存服务器,把客户经常访问的内容放在其上,这样客户就可以直接在高速缓存服务器上获取这些内容,从而降低了网络拥塞。这样就有更多的带宽去处理其他请求,极大地缩短了响应时间。
负载均衡服务器:随着网站通信量的增加,一台服务器已经不能满足业务需求,需要不断增加新的服务器,并要跨越这些服务器分发负载,同时还不能造成站点访问者的任何中断。这些访问应该连接到相同的URL- 不管实际上是由哪一台服务器来满足了请求.这就需要一个专用服务器动态分配个服务器之间的访问流量,这种服务器就是负载均衡服务器。 负载均衡服务器通过特定的负载均衡技术,将客户发出的请求视同一功能的服务器组中各服务器的负载情况合理地分配到某一台服务器上,籍此大大提高获取数据的速度。解决海量并发访问问题。负载均衡服务器不仅可以动态分配流量,还可以检测服务器的使用情况,如果某台服务器发生了故障,那么负载均衡服务器就会把该服务器的工作分配到其他服务器上去,保证系统运行的高可用性和高可靠性。
-
-
什么是CDN?
content deliver network,内容分发网络,是建立并覆盖在承载网之上,由分布在不同区域的边缘节点服务器群组成的分布式网络。
CDN的全称是Content Delivery Network,即内容分发网络。CDN是构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。CDN的关键技术主要有内容存储和分发技术。
CDN将用户经常访问的静态数据资源直接缓存到节点服务器上,当用户再次请求时,会直接分发到在离用户近的节点服务器上响应给用户,当用户有实际数据交互时才会从远程Web服务器上响应,这样可以大大提高网站的响应速度及用户体验。
CDN网络的诞生大大地改善了互联网的服务质量,因此传统的大型网络运营商纷纷开始建设自己的CDN网络。
因此,如果目标服务器使用了CDN服务,那么我们直接查询到的IP并不是真正的目标服务器的IP,而是一台离你最近的目标节点的CDN服务器,这就导致了我们没法直接得到目标服务器的真实IP。
过程
-
判断是否用了CDN
-
nslookup:发现返回时多个IP的话,多半使用了CDN
-
ping: ping某个网站发现显示的是在ping其他网站,那么也就是说使用了CDN
-
也可以使用设置代理或者使用在线从不同区域对目标进行ping,然后对比每个地区IP结果,如果一致就没有,如果不一致那么很可能就是使用了CDN,下面是一些在线网站
站长工具:http://ping.chinaz.com/
全球ping:https://www.wepcc.com
17CE:https://www.17ce.com
IPIP:https://www.ipip.net/ip.html
-
-
如何找到真实IP
-
利用子域名。
通常站长只给主网站或者是访问流量大的网站使用了CDN,但是一些流量小的网站可能没有挂CDN,这些分站和主站虽然不是同一个IP但是是同一个C段,所以我们可以ping二级域名获取分站IP,从而判断真实IP
-
查询主域。
以前用CDN的时候有个习惯,只让WWW域名使用cdn,秃域名不使用,为的是在维护网站时更方便,不用等cdn缓存。所以试着把目标网站的www去掉,ping一下看ip是不是变了
-
网站漏洞。
网站存在漏洞导致敏感信息泄露,扫描网站敏感信息,phpinfo敏感信息泄露、Apache status和Jboss status敏感信息泄露、网页源代码泄露、svn信息泄露信、github信息泄露等。
若存在web漏洞,服务器主动与我们发起请求连接,我们也能获取目标站点真实ip。例如xss、ssrf、命令执行反弹shell等。
-
从国外访问。
国内很多CDN厂商因为各种原因只做了国内的线路,而针对国外的线路可能几乎没有,此时我们使用国外的主机直接访问可能就能获取到真实P。我们可以通过国外在线代理网站访问,可能会得到真实的IP地址,外国在线代理网站:
https://asm.ca.com/en/ping.php
-
通过邮件服务器。
一般的邮件系统都在内部,没有经过CDN的解析,通过目标网站用户注册或者RSS订阅功能,查看邮件,寻找邮件头中的邮件服务器域名IP,ping这个邮件服务器的域名,由于这个邮件服务器的有可能跟目标Web在一个段上,我们直接一个一个扫,看返回的HTML源代码是否跟web的对的上,就可以获得目标的真实IP(必须是目标自己内部的邮件服务器,第三方或者公共邮件服务器是没有用的)。
很多站点都有发送邮件sendmail的功能,如Rss邮件订阅等。而且一般的邮件系统很多都是在内部,没有经过CDN的解析。可在邮件源码里面就会包含服务器的真实 IP。
-
历史DNS记录
通过查询DNS记录可能找到在使用CDN之前的IP
-
利用网络空间搜索引擎。
这里主要是利用网站返回的内容寻找真实原始IP,如果原始服务器IP也返回了网站的内容,那么可以在网上搜索大量的相关数据。
-
端口信息收集
在渗透测试的过程中,收集端口信息是一个十分重要的过程,通过扫描目标服务器开放的端口可以从该端口判断服务器上运行的服务。
因为针对不同的端口具有不同的攻击方法,收集端口信息可以对症下药,便于我们渗透目标服务器。
手工探测
-
nmap
nmap -A -v -T4 -O -sV 目标地址
-
masscan
Masscan号称是最快的互联网端口扫描器,最快可以在六分钟内扫遍互联网。masscan的扫描结果类似于nmap(一个很著名的端口扫描器),在内部,它更像scanrand, unicornscan, and ZMap,采用了异步传输的方式。它和这些扫描器最主要的区别是,它比这些扫描器更快。而且,masscan更加灵活,它允许自定义任意的地址范和端口范围。
在线探测
在线网站:http://tool.chinaz.com/port/
ThreatScan在线网站(网站基础信息收集):https://scan.top15.cn/
Shodan:https://www.shodan.io/
存疑
- waf探测